
Du kannst dir 121WATT-Inhalte in der Google-Suche jetzt bevorzugt anzeigen lassen.
Über externe und interne Verlinkungen gelangen sie von Seite zu Seite.
Step 2: Indexing
Die gefundenen Inhalte kommen anschließend in den Index (sofern andere Faktoren das nicht verhindern). Ist eine Seite im Index, können User:innen sie bei Google finden.
Step 3: Ranking
Stellt ein:e Nutzer:in eine Suchanfrage, sucht Google im Index nach den relevantesten Dokumenten zu diesem Thema und stellt sie über die Suchergebnisseiten (SERP) zur Verfügung.
Vereinfacht sieht das so aus:
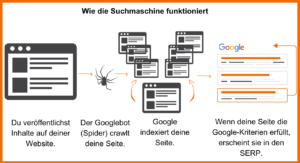
Für alle, die mehr in die Technik gehen möchten, zeige ich das folgende Schaubild:
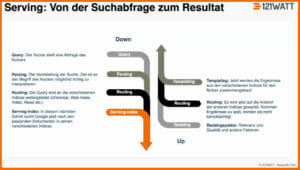
Google erklärt diesen Prozess sehr ausführlich auf seinen Infoseiten.
Trotz dessen Google eine der größten Rechenkapazitäten weltweit besitzt, so priorisiert der Suchgigant sein Crawling und Indexing. Welche Möglichkeiten hast du nun, um Google auf eine neue URL auf deiner Seite aufmerksam zu machen? Hier sind vier Möglichkeiten:
Ist deine Website neu? Dann kann es einige Zeit dauern, bis sie vollständig indiziert ist. Wenn sie allerdings schon länger online ist, dann kannst mit einfachen Bordmitteln analysieren, ob Google deine Seite kennt:
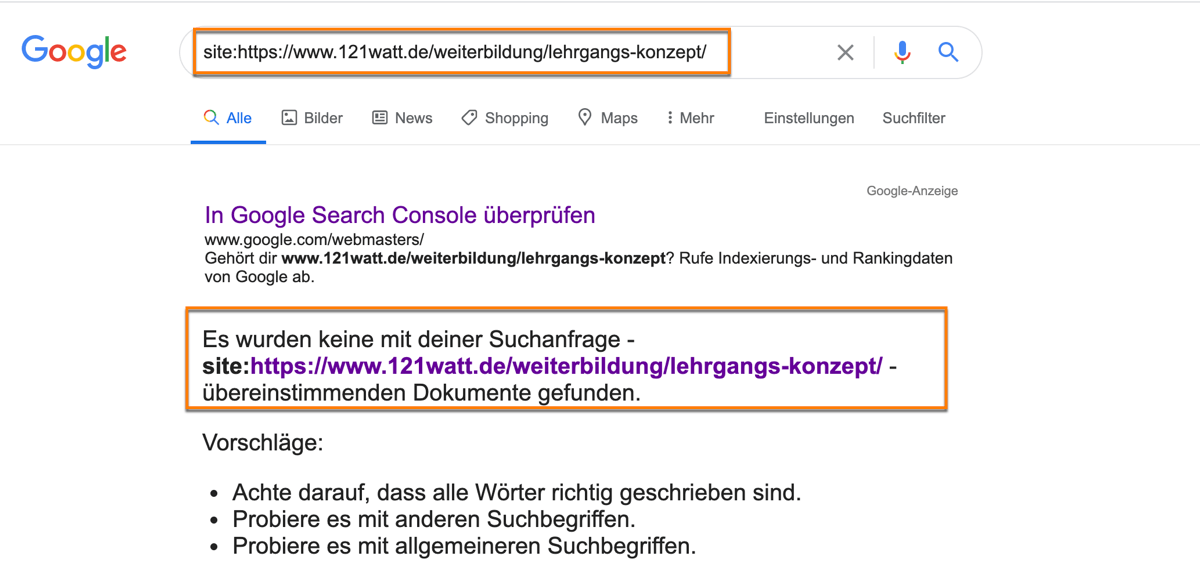
Gebe „site:deinewebsite.de“ (ersetze deinewebsite.de durch deine Domain) in die Google-Suche ein und schon siehst du, ob deine Seite indiziert wurde, wenn Google sie als Ergebnis anzeigt. Hier siehst du, wie das dann aussehen kann.
Mit dem kostenlosen Tool von Google, kannst du die Indexierung deiner Website überprüfen.
Die ganze Website generell überprüfen
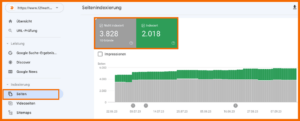
Dafür gehst du im Menü der GSC links auf Seiten im Bereich Indexierung. Dann werden dir alle Seiten deiner Website angezeigt die indexiert (grün) und nicht indexiert (grau) sind. Keine Sorge, der hohe, nicht indexierte Anteil bei uns ist so gewollt.
Eine bestimmte (Unter-)seite überprüfen
Möchtest du den Indexierungsstatus nur für eine bestimmte URL erhalten (und gleich detaillierte Infos zum Status), dann gehst du am besten über die URL-Prüfung (früher URL-Inspector) und gibst hier die relevante Adresse ein. In einem ersten Schritt, analysiert Google die URL und gibt dir ein Feedback zur entsprechenden Seite. In dem folgenden Screenshot siehst du, wie das aussehen könnte:
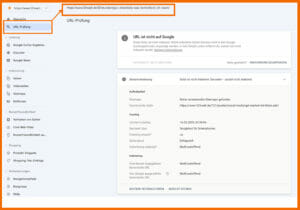
Handelt es sich bei dir um eine komplett neue URL, dann kann dir Google folgendes Feedback geben:
URL ist nicht auf Google: Diese Seite ist nicht im Index, aber nicht aufgrund eines Fehlers. Du hast über die GSC allerdings die Möglichkeit eine Indexierung direkt bei Google zu beantragen. Dafür klickst du im nächsten Schritt auf der rechten Seite auf „Indexierung beantragen“. Dieser Prozess dauert ca. 1-2 Minuten und du bekommst dann als Meldung, das deine URL einer bevorzugten Crawling-Warteschlange hinzugefügt wurde.
Tipp für Fortgeschrittene: Seit dem Februar 2022 kannst du diese Daten über die URL-Inspection API auch in andere Tools wie dem ScreamingFrog ziehen und systematische Analyse deines Crawling- und Indexierungs-Status durchführen. Mehr Informationen findest du bei Google oder in dem folgenden Artikel darüber wie du diese Daten für den URL-Inspection API im ScreamingFrog nutzt.
Nach einer gründlichen Prüfung stellst du fest: Meine Seite ist nicht im Index, obwohl ich das gerne möchte! Deswegen werfen wir jetzt einen Blick auf die häufigsten Gründe, warum Seiten nicht von Google indiziert werden und wo du ansetzen kannst, um (wieder) indexiert zu werden:
Herausforderung: Deine Seite wurde nicht gefunden
Google war nicht in der Lage, deine Seite auf der Website zu finden und konnte sie deswegen nicht indexieren und ausgeben. Dafür gibt es drei Hauptgründe:
Wenn die Googlebots deine Website durchsuchen, folgen sie Links, um neue Seiten zu entdecken und zu indizieren. Interne Links, d. h. Links, die Seiten innerhalb einer Website miteinander verbinden, helfen Robotern wie dem Googlebot, auf einer Website zu navigieren und ihre Struktur zu verstehen. Hast du deine Seiten untereinander nicht verlinkt, dann haben die Bots der Suchmaschinen möglicherweise Schwierigkeiten, alle Seiten zu finden, was dazu führen kann, dass einige Seiten nicht indiziert werden.
Eine Sitemap ist eine Datei, die die wichtigsten indizierbaren Seiten einer Website auflistet (oder in manchen Fällen alle). Suchmaschinenroboter können eine Sitemap verwenden, um Inhalte der Website zu finden und zu indizieren.
Ist eine bestimmte Seite nicht in der Sitemap enthalten, bedeutet das nicht automatisch, dass sie von Suchmaschinen nicht indiziert wird. Es kann allerdings für Suchmaschinenroboter schwieriger sein, sie zu finden und zu crawlen. Der Bot könnte eine fehlende Seite möglicherweise als weniger wichtig erachten oder sie in der Hierarchie niedriger einstufen und damit außer Acht lassen.
Nimm daher alle Seiten, die dir wichtig sind, in die Sitemap auf: Die Seite ist leichter auffindbar und ihr Vorhandensein in der Sitemap ist ein Hinweis darauf, dass diese Seite wichtig ist und indiziert werden sollte.
Bedenke, dass der Googlebot deine Website durchsucht, um ihren Inhalt zu indizieren. Dafür hat er nur eine begrenzte Zeit zur Verfügung (Crawlbudget). Ist deine Website groß und lädt zu allem Überfluss auch noch langsam, dann kann das Crawlen eine Herausforderung für die Suchmaschinen-Bots darstellen. Du kannst dir sicher vorstellen, dass die Robots nicht in der Lage sind, alle Seiten innerhalb des vorgegebenen Zeitlimits zu indizieren.
Herausforderung: Deine Seite wurde nicht gecrawlt
Wenn Bots eine Website crawlen, entdecken sie neue Seiten und Inhalte, die in den Google-Index aufgenommen werden können. Dieser Vorgang ist wichtig, um sicherzustellen, dass die Seiten in den Suchergebnissen angezeigt werden. Wenn eine Seite jedoch nicht gecrawlt wird, wird sie auch nicht in den Index der Suchmaschine aufgenommen. Es gibt mehrere Gründe, warum eine Seite von einer Suchmaschine nicht gecrawlt werden kann; dazu gehören ein geringes Crawl-Budget, Fehler oder die Tatsache, dass die Seite in der robots.txt nicht zugelassen ist.
Die Datei robots.txt ist eine Textdatei, mit der Suchmaschinenroboter angewiesen werden, Seiten oder Verzeichnisse auf deiner Website zu crawlen oder nicht zu crawlen. Über die robots.txt-Datei kannst du oder dein:e Website-Administrator:in Suchmaschinen zeigen, welche Inhalte für das Crawlen zugänglich sein sollen und welche nicht.
Generell gilt: Wenn du eine Seite in der robots.txt-Datei ausschließt, können Suchmaschinen-Bots diese Seite nicht crawlen und indexieren. Es gibt jedoch Sonderfälle: Ist deine Seite beispielsweise von einer externen Ressource verlinkt, dann kann sie indexiert werden, obwohl sie in der robots.txt-Datei blockiert ist.
Stellst du fest, dass deine Seite überhaupt nicht gecrawlt wurde, könnte es daran liegen, dass du sie versehentlich mit einer robots.txt-Datei blockiert hast.
Du hast Google per noindex ausgesperrt
Möglicherweise hindert das Meta-Tag „Robots“ mit dem Wert „noindex“ Google daran, deine Seite zu indexieren. Möchtest du das ändern, entfernst du den Wert „noindex“. Meistens werden diese Einstellungen über dein Content Management System vorgenommen. Hinweis: Der noindex-Befehl befindet sich im Head-Bereich deiner Website und sollte ungefähr so aussehen:
<meta name="robots" content="noindex" />
Ein einfaches Tool, um die falsche Auszeichnung über ein „noindex“ festzustellen ist die Extension META SEO inspector. Im folgenden Screenshot siehst du, wie das entsprechend für diese Seite aussieht. Neben vielen relevanten Daten, die euch bei der Suchmaschinenoptimierung helfen, wie Titel, Description etc. findest du weiter unten die Angabe, ob deine Seite auf „index“ oder „noindex“ gesetzt ist.

Du hast Crawler per robots.txt generell ausgesperrt
Wenn sich im Rootverzeichnis deiner Domain eine Datei namens robots.txt befindet, welche die folgenden Zeilen beinhaltet, hast du sowohl Googles Crawler als auch allen anderen Crawlern die Sicht auf deine Seite verwehrt:
User-Agent: *
Disallow: /
Entfernst du diese beiden Zeilen, dann kann deine Seite wieder gecrawlt und damit auch indexiert werden. Du kannst die robots.txt Datei recht einfach auslesen, indem du einfach hinter deine Domain bzw. Startseite ein /robots.txt anhängst. Auf diese Weise kannst du überprüfen, welche Verbote hier ggf. hinterlegt sind. So sieht das bei uns aus: https://www.121watt.de/robots.txt . Üblicherweise schließt man zum Beispiel Seiten aus, wie
Mehr zur robots.txt und welche Seiten du dort unbedingt ausschließen solltest und welche besser nicht, das findest du beim Searchenginejournal.
Du hast nur Googles Crawler per robots.txt ausgesperrt
Es ist mit der robots.txt auch möglich, Crawler spezifisch auszusperren. In diesem Falle lautet der Eintrag beispielsweise:
User-Agent: Googlebot
Disallow: /
Entfernst du diesen Eintrag, kann fröhlich weiterindexiert werden.
Deine Pagination ist SEOseitig nicht korrekt eingestellt
Falls eine Unterseite deiner Website nicht erreichbar ist, kann das daran liegen, dass die Pagination mit nofollow belegt ist.
Einzelne Links stehen auf nofollow
Es ist ebenso möglich, dass einzelne Links per nofollow nicht erreichbar sind. Du kannst das überprüfen, indem du den Head deiner Seite nach folgender Sequenz durchsuchst:
<meta name="robots" content="nofollow" />Das Crawl-Budget bezieht sich auf die Anzahl der Seiten oder URLs, die von den Googlebots innerhalb eines bestimmten Zeitraums gecrawlt und indexiert werden. Wenn das einer Website zugewiesene Crawl-Budget zu niedrig ist, bedeutet dies, dass der Crawler der Suchmaschine nicht in der Lage sein wird, alle Seiten sofort zu crawlen und zu indizieren. Das bedeutet, dass einige Seiten der Website möglicherweise nicht in den Suchergebnissen auftauchen.
Du kannst allerdings Einfluss auf dein Crawl-Budget nehmen. Das Budget wird in der Regel von der Suchmaschine auf der Grundlage mehrerer Faktoren festgelegt, die sich negativ auswirken können:
Wenn ein Googlebot versucht, deine Webseite zu crawlen, sendet er eine Anfrage an den Server, der die Website hostet, um den Inhalt der Seite abzurufen.Wenn der Server auf ein Problem stößt, antwortet er mit einem Serverfehlercode, der angibt, dass er den angeforderten Inhalt nicht bereitstellen konnte. Der Googlebot interpretiert dies als eine vorübergehende Nichtverfügbarkeit oder als ein Problem mit der Website, was das Crawling verlangsamen kann.
Wenn das bei dir der Fall sein sollte, dann werden einige deiner Seiten möglicherweise nicht von der Suchmaschine indiziert. Kommt dieses Verhalten wiederholt vor, kann dies außerdem dazu führen, dass Seiten aus dem Index gestrichen werden.
Ob deine Website erhebliche Serverprobleme aufweist, kannst du in einem der GSC-Berichte überprüfen.
Weitere Informationen und Empfehlungen zur Behebung dieses Problems:
Wenn du überprüfen möchtest, wie sich bestimmte Statuscodes (einschließlich Serverfehler) auf das Verhalten von Googlebots auswirken, kannst du dies in der offiziellen Dokumentation von Google nachlesen: Wie HTTP-Statuscodes, Netzwerk- und DNS-Fehler die Google-Suche beeinflussen.
121-Stunden Online-Marketing Newsletter:
Keine SEO- und Online-Marketing-News mehr verpassen!
Herausforderung: Google hat deine Seite nicht indexiert oder deindexiert
In diesem Fall erscheint deine Seite nicht bei Google, weil sie einfach nicht indexiert oder deindexiert wurde. Dies kann durch technische Probleme, minderwertige Inhalte, Verstöße gegen Richtlinien oder sogar manuelle Maßnahmen verursacht worden sein:
Es ist selten, kommt aber vor: Meta-Tags können aufgrund eines Entwicklungsfehlers versehentlich auf „noindex, nofollow“ gesetzt worden sein. Infolgedessen wird deine Seite möglicherweise aus dem Index entfernt oder gar nicht erst indexiert. Denn ein Noindex-Meta-Tag weist Google schließlich an, diese spezielle Seite nicht zu indexieren.
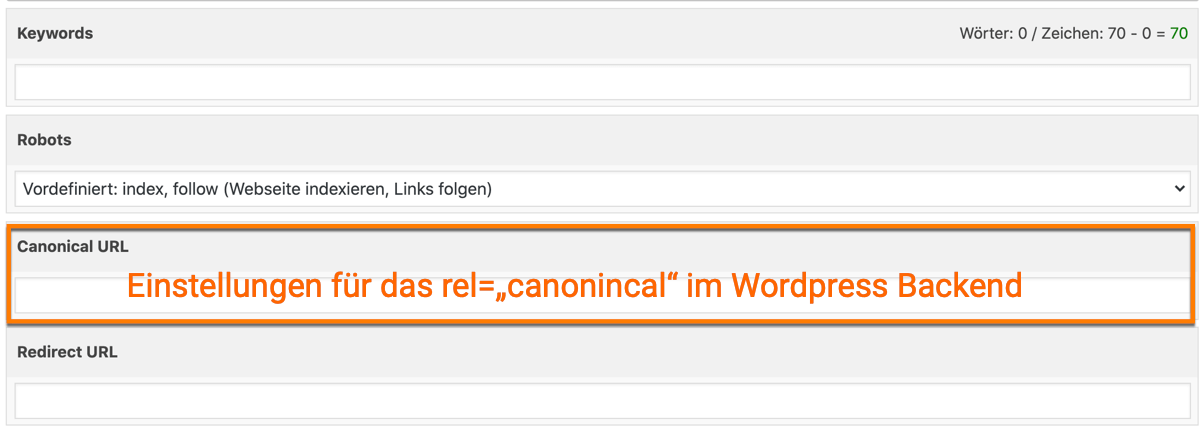
Mit dem Canonical-Tag (rel=canonical) kannst du dafür sorgen, dass bei mehreren URLs mit gleichem oder ähnlichem Inhalt nur eine URL (Quelle) zur Indexierung verwendet wird. Dieses Tag setzt du also ein, wenn der Inhalt der Seite ein Duplikat oder eine Variation einer anderen Seite auf der Website ist.
Hast du das kanonische Tag nicht korrekt implementiert, dann kann es zu Problemen bei der Indexierung führen. Wenn zum Beispiel nach einem Relaunch das Canonical auf eine andere URL verweist, führt das dazu, dass die Ursprungs-URL nicht korrekt indexiert werden kann. Auch hier führt dich der Weg in die Google Search Console. Du überprüfst die URL, die du gerne im Index von Google finden möchtest. Ich habe für dieses Beispiel eine URL genommen, die wir mit Absicht nicht im Index von Google haben möchten. Du siehst, auch hier sagt Google wieder „URL ist nicht bekannt“, aber der Grund liegt darin, das Google von einer anderen URL als der richtigen URL ausgeht ( vom Nutzer angegebene kanonische URL).
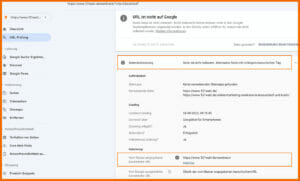
Wenn du das mit Absicht über das sogenannte rel=“canonical“ Google angezeigt hast, dann ist alles in Ordnung. Vielleicht hast du aber in deinem Content Management System aus Versehen ein rel=“canonical“ angegeben. Dann kann es dir passieren, das Google deine Seite zwar crawlt, aber nicht indexiert. Was machst du jetzt? Du gehst in dein Content Management System und überprüfst in den Einstellungen für deine URL, ob du hier vielleicht ein rel=“canonical“ auf eine andere Seite gesetzt hast. Meistens werden diese Einstellungen über Plugins ermöglicht. Wenn du das nicht wolltest, dann entferne jetzt das rel=“canonical“ und gebe die URL erneut Google zum Crawling.
Wenn deine Seite ein Duplikat einer anderen Seite ist, wird sie vom Googlebot möglicherweise nicht indiziert. Und selbst wenn, dann lassen Suchmaschinen es normalerweise nicht zu, dass doppelte Inhalte gut platziert werden.
Beachte auch, dass doppelte Inhalte sich auf das Crawl-Budget deiner Website auswirken können. Der Googlebot muss jede URL crawlen, um festzustellen, ob sie denselben Inhalt haben. Das verbraucht mehr Zeit und Ressourcen, weswegen der Bot ggf. weniger Kapazität für das Crawlen anderer, wertvollerer Seiten hat.
Du kannst dir sicher vorstellen, dass Aktionen wie das Kopieren von Inhalten von anderen Websites oder das erneute Veröffentlichen von Inhalten ohne zusätzlichen Wert in der Welt der Suchmaschinenoptimierung nicht willkommen sind. So etwas kann sich durchaus negativ auf dein Ranking auswirken.
Tipp: Du kannst leicht herausfinden, ob du Duplicate Content bereitstellst, indem du einen Satz aus dem fraglichen Text nimmst und in Anführungszeichen bei Google suchst oder deine URL bei Copyscape auf DC überprüft.
Exkurs: „Gecrawlt – zurzeit nicht indexiert“: Im Zusammenhang mit Duplicate Content wird übrigens öfter der Status „gecrawlt – zurzeit nicht indexiert“ erwähnt. Wenn du in der GSC auf der Ansicht der Seitenindexierung weiter nach unten scrollst, siehst du warum deine Seite nicht indexiert wurde:
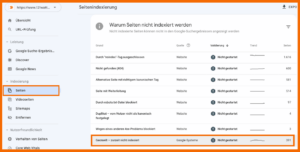
Einer der möglichen Gründe ist, dass deine Seite gecrawlt, aber zurzeit nicht indexiert wurde. Dieser Status ist in der Google-Hilfe nicht exakt beschrieben. Die Gründe, die hier genannt werden sind:
Du kannst zum Beispiel mit dem ScreamingFrog alle deine Seite analysieren und bewerten. Interessant sind hier die
Mit großer Sicherheit findest du hier viele deiner Seiten, die von Google gecrawled, aber nicht indexiert wurden.
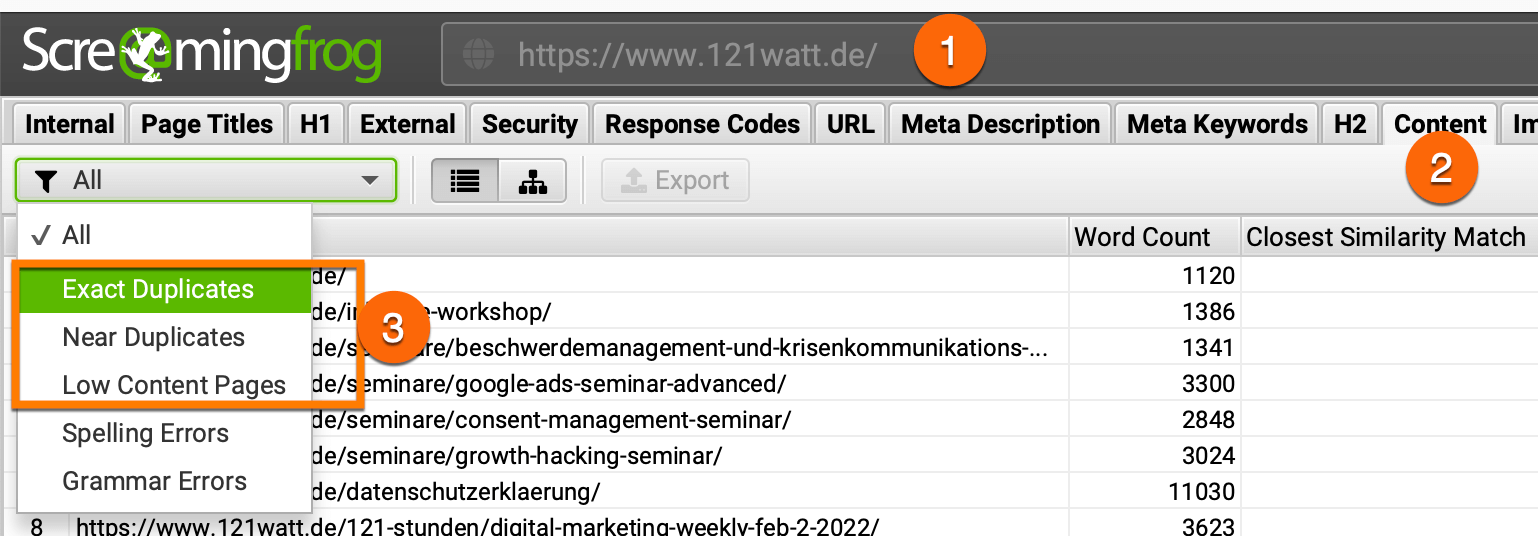
Was ist die Lösung für diesen Status?
Die Lösung hat in diesem Fall hauptsächlich mit deinen Inhalten zu tun, gerade wenn es um wichtige Seiten geht, die hier nicht indexiert wurden. Versuche bei deinen Inhalte an folgenden Punkten zu arbeiten:
Diese Vorschläge von mir für dich, basieren auf den Google General Guidelines, die eine große Hilfe für die Entwicklung guter Inhalte darstellt. Hier findest du auch noch einen sehr umfangreichen Artikel zu „gecrawled – zurzeit nicht indexiert“ und mehr Informationen in der Google Hilfe
Google stuft Inhalte von schlechter Qualität in der Regel als nicht wertvoll für die Nutzer:innen ein und indexiert diese Seite dann einfach nicht. Außerdem kann qualitativ schlechter Inhalt zu einer hohen Absprungrate führen, d. h. deine Nutzer:innen verlassen die Seite schnell, ohne mit ihr zu interagieren. Dies kann Google signalisieren, dass diese Seite irrelevant oder nicht wertvoll für die User:innen ist, was dazu führt, dass sie nicht indexiert wird.
Der HTTP-Statuscode ist Teil einer Antwort, die ein Server an einen Client sendet, nachdem er eine Anfrage zum Zugriff auf eine Webseite erhalten hat. Der HTTP-Statuscode 200 (= OK) zeigt an, dass der Server erfolgreich auf die Anfrage geantwortet hat und die Seite zugänglich ist.
Wenn deine Seite einen anderen HTTP-Statuscode als 200 OK zurückgibt, wird sie nicht indiziert. Warum das so ist, hängt vom jeweiligen Statuscode ab. Ein 404-Fehlerstatuscode zeigt beispielsweise an, dass die angeforderte Seite nicht gefunden wurde, und ein 500-Fehlerstatuscode bedeutet, dass ein interner Serverfehler aufgetreten ist. Erhält nun der Googlebot beim Crawlen deiner Seite diesen Fehler, dann geht er davon aus, dass die Seite nicht verfügbar oder nicht funktionsfähig ist, und wird sie nicht indizieren.
Sollte deine Seite neu sein oder generell geringen Datenverkehr aufweisen, kann es sein, dass sich diese Seite in der Indizierungswarteschlange befindet und damit noch nicht indexiert ist. Dieser Vorgang kann einige Zeit in Anspruch nehmen und er kann sich weiter verzögern, wenn die Website technische Probleme, ein geringes Crawl-Budget oder Robots.txt-Ausschlüsse oder andere Einschränkungen aufweist.
Wenn deine Website viele Seiten hat, kann Google außerdem möglicherweise nicht alle auf einmal indizieren. Dies kann dazu führen, dass einige Seiten länger in der Indexierungswarteschlange verbleiben.
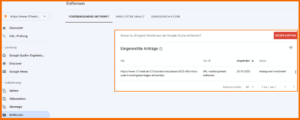
Vielleicht hast du oder jemand aus deinem Unternehmen beabsichtig oder unbeabsichtigt eine URL über die Google Search Console aus dem Google Index entfernt. Am Ende wurde von jemandem beantragt, dass deine Seite aus dem Index entfernt wird. Um das herauszufinden, loggst du dich in die Google Search Console ein und klickst auf Indexierung -> Entfernen. Taucht dort keine URL auf, ist dies jedenfalls nicht der Grund für die Unauffindbarkeit deiner Seite. Hier siehst du ein Beispiel, wie eine entfernte URL in der Google Search Console gelistet wird.
Wenn der Googlebot eine Seite crawlt, ruft er nicht nur den HTML-Inhalt ab, sondern rendert die Seite auch wie ein Browser. Stößt der Googlebot beim Rendern auf Probleme, dann kann er den Seiten-Inhalt eventuell nicht richtig verstehen. Er kann dann ggf. bestimmte Elemente wie JavaScript-generierte Inhalte oder strukturierte Daten nicht erkennen, die für die Indexierung und das Ranking wichtig sind.
Mehr zu den Grundlagen von JavaScript-SEO liest du bei Google direkt.
Beachte auch, dass solche fehlerbehaftete Seiten von Google schnell als Duplikate oder minderwertig eingestuft und möglicherweise deswegen nicht indiziert werden können.
Hierauf wirst du in der Search Console meistens hingewiesen. Wirf deshalb immer einen Blick auf Benachrichtigungen oben rechts oder schau dir die Sicherheitsbenachrichtigungen in der linken Navigation an. Alternativ dazu empfehle ich dir den Anti-Malware SaaS Sucuri – dieser Dienst überwacht deine Website ständig und informiert dich bei Problemen und hilft bei der Lösung!
Der Tool-Anbieter ahrefs hat über 1 Millionen Domains analysiert und die 15 häufigsten Technical SEO-Probleme zusammengestellt. Ganz vorne mit dabei sind die fehlerhaften Weiterleitungen und fehlende Alt-Tags.
Passieren Fehler in der Suchmaschinenoptimierung? Aber natürlich, deswegen habe ich mir angewöhnt in regelmäßigen Abständen einen SEO-Audit auf meiner Seite zu machen. Das Ziel: Eine hohe Sichtbarkeit in den Suchmaschinen. In meinem Artikel zur Definition, Analyse und Verbesserung deiner Sichtbarkeit in der Suchmaschinenoptimierung findest du alle relevanten Informationen zur Beurteilung deiner Sichtbarkeit.
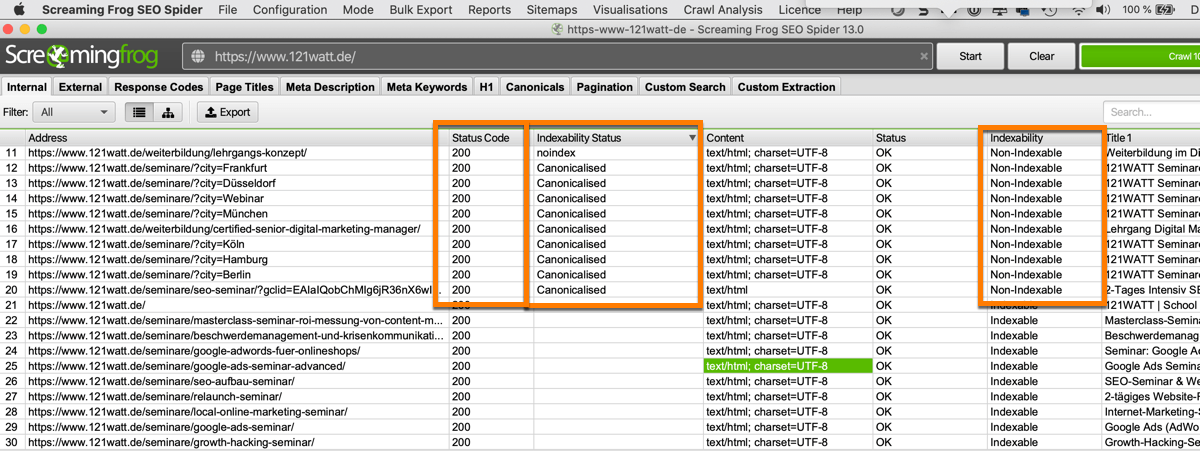
Hier siehst du einen Screenshot meines wöchentlichen SEO-Audits im ScreamingFrog. Besonders schaue ich mir die HTTP-Statuscodes, den Indexierungsstatus und die Indexierbarkeit an. Bei Problemen mit Weiterleitungen, falsch gesetzten NoIndex Anweisung, Ausschluss durch robots.txt, rel=“canonical“ etc. verfahre ich dann, wie hier in diesem Artikel dargestellt.
Natürlich ist es möglich, dass keiner der oben genannten Fehler Auslöser einer mangelnden Indexierung sind. Die beschriebenen Ursachen decken allerdings die häufigsten Fehlerquellen ab. In jedem Fall solltest du nicht in Panik verfallen, wenn deine Website plötzlich nicht mehr in den SERPs auftaucht. Nimm dir eine Tasse Kaffee und gehe diesen Artikel Schritt für Schritt durch. Ich bin sicher, du findest die Lösung – falls nicht, schau gerne direkt bei Google in der Dokumentation nach, hol‘ dir umfangreiches Wissen in einem unserer Technical SEO Seminare oder frag mich auf LinkedIn, Instagram & Co. ;-)
Dein Feedback hilft uns, unsere Inhalte noch besser zu machen.
Schade! Bitte schreib uns kurz, was dir gefehlt hat – so werden wir besser.


Hallo :),
die Webseite hier ist total witzig. Aber eine Sache verstehe ich nicht. Wenn oben nicht die Lösung steht, was soll man in deinen Seminaren? Trinken wir dort in Ruhe Kaffee und lernen wir Milch einschütten oder besser einen Ausrufe-Crashkurs: Sehhhhh Ohhhhh
In diesem Sinne
Alles Gute
Jörg
P.S: Falls Du noch eine korrekte Antwort finden solltest, schreib mir eine Mail bitte!
Hallo Jörg,
dieser Artikel ist nur ein kleines und sehr spezielles Thema im Bereich der SEO. Ein ganzes Seminar soll und kann er auch gar nicht ersetzen. Er soll denen, die nach diesem Problem suchen und uns dabei finden, helfen, die Antwort zu erfahren. Ich hoffe, dass uns das auch gelingt.
Unsere Seminare dauern 8, respektive 16 Stunden. Sei versichert, dass die dort behandelten Themen umfassend behandelt werden.
Kaffee gibt es dort übrigens auch. Mit und ohne Milch.
Auch Dir alles Gute
Christian
Hallo,
ich gehe schon mal davon aus, dass man viel in Euren Seminaren lernen kann. Aber ich möchte mal einen Punkt anbringen, den Euer Artikel wohl nicht abdeckt. Folgender Fall bei einem Kunden:
Seite ist nicht indexiert
Seite ist nicht im Report: gecrawlt – zur Zeit nicht indexiert
Soweit alles klar (die übergeordnete Kategorienseite wurde zur Indexierung eingereicht).
Nun kommt meine Frage: im Leistungsreport => Seitenansichten taucht genau die Seite mit 200 Impressions auf. Google hat sie weder gecrawlt noch indexiert und gibt sie dennoch in Suchergebnissen der Search Console aus? Habt Ihr dafür eine plausible Erklärung? (Die Seite wurde vor vier Wochen unter eine neue Kategorie gestellt, die geänderte URL erhält eine Weiterleitung von der alten URL, die aber auch nicht indexiert war. An der Inhaltsquaalität kanns nicht liegen, tausende ähnlich aufgebauter Seiten sind indexiert).
Vielen Dank – freue mich, wenn Ihr eine Erklärung habt.
Grüße
Gerd
Hallo lieber Gerd, danke für deine Frage. Ich glaube ohne jetzt ganz den konkreten Fall zu kennen (vielleicht kannst du mir mal die Seiten via alexander.holl@121watt.de) zu schicken, war meine erste Idee, das es mit der Zählung der Impressionen in der Google Search Console zu tun haben könnte. Hier ist ja mal die Definition: Klick-, Impressions- und Positionsdaten werden, sofern verfügbar, der kanonischen URL der Seite zugeordnet, auf die der Nutzer weitergeleitet wird, wenn er auf den Link im Browser klickt. Die kanonische URL ist im Wesentlichen eine einzelne URL, die von Google ausgewählt wird, wenn mehrere URLs auf dieselbe Seite verweisen. Dies ist zum Beispiel der Fall, wenn eine Website separate URLs für die mobile und die Desktopversion einer Seite hat. Hier auch der Link https://support.google.com/webmasters/answer/7042828?hl=de#impressions. Aber das ist nur der erste Anasatz für die Analyse, also vielleicht kannst du mir mal die betreffende Seite zuschicken. Liebe Grüße aus München Alexander