
Du kannst dir 121WATT-Inhalte in der Google-Suche jetzt bevorzugt anzeigen lassen.
❓Filterst du noch oder RegExt du schon❓
Eine berechtigte Frage, denn mit regulären Ausdrücken kannst du in deiner Web-Analyse meist umfangreicher und differenzierter filtern als mit normalen Filter-Funktionen. In diesem Artikel klären wir, was reguläre Ausdrücke sind, welche 12 regulären Zeichen du kennen solltest und zeigen mit einfachen Beispielen, wie du sie anwenden kannst.
Reguläre Ausdrücke sind eine Kette von Zeichen (auch Pattern genannt), welche die Suche nach bestimmten Mustern in Zeichenfolgen ermöglichen. Sie finden überwiegend in der Softwareentwicklung Verwendung, sind aber auch in SEO wichtige Analyse-Tools. Du kannst mit ihnen nach bestimmten Mustern in Keywords, URLs oder anderen Inhalten filtern.
Anwenden kannst du die RegEx u.a. in:
1. ( )
Die Klammern werden – wie wir in Algebra gelernt haben – verwendet, um Gruppen zu bilden. Ein Anwendungsbeispiel findest du beim nächsten Punkt.
2. |
Das Pipe-Symbol steht für den Begriff oder.
Aber Vorsicht – wenn du es am Ende verwendest, bedeutet es “oder was auch immer”.
Beispiel: Du möchtest im Keywordbericht von Sistrix nach Onlinemarketing oder Onlinewerbung suchen, dann ist ein möglicher RegEx: Online(werbung|marketing)
3. .
Der Punkt ist ein Platzhalter und steht somit für ein beliebiges Zeichen
Das Platzhalterzeichen bedeutet, dass es mit einem beliebigen Zeichen übereinstimmt. Es kann eine Zahl, ein Buchstabe, ein Sonderzeichen oder sogar ein Leerzeichen sein
Beispiel: a.c passt auf “aac”, “akc”, “a9c”, aber nicht auf “ac”, oder “ab4c”.
Der Punkt wird oft mit dem Asterisk * oder Pluszeichen verwendet +.
4: *
Das Sternchen steht für kein oder beliebig viele Zeichen
Der Asterisk bedeutet, dass er mit keiner oder einer beliebigen Anzahl des vorangegangenen Zeichens oder der vorangegangenen Gruppe übereinstimmen muss.
Beispiel: 1* passt auf: “”, “1”, “11”, “111” usw.
5: +
Das Plus steht für ein oder beliebig viele Zeichen
Es wird ähnlich verwendet, wie das Sternchen, mit dem Unterschied, dass mindestens ein Zeichen übereinstimmen muss.
Beispiel: o+ passt auf “o”, “oo”, “ooo” usw., aber nicht auf “”
6: \
Der Backslash steht dafür, dass ein darauf folgendes Sonderzeichen wie ein Buchstabe behandelt wird. Du verwendest ihn also, wenn du verhindern möchtest, dass ein Sonderzeichen als regulärer Ausdruck interpretiert wird.
Beispiel: Bei URLs musst du vor den Punkten den umgekehrten Schrägstrich einfügen: www\.121watt\.de
7. ?
Das Fragezeichen macht den vorhergegangenen Ausdruck optional.
Das bedeutet, dass das vorherige Zeichen kein oder einmal auftreten kann.
Beispiel: Wenn du nach allen Keywords filtern möchtest, die “Tchibo” und die falsche Schreibweise “Tschibo” inkludieren, verwendest du den regulären Ausdruck: .*ts?chibo.*
.* bedeutet, dass dort keine bis beliebig viele verschiedene Zeichen stehen dürfen. ? vor dem s bedeutet, dass das s optional ist. So erhältst du alle Suchanfragen, in denen Tchibo oder Tschibo vorkommt, egal was davor oder danach steht.
8: ^
Das Dachsymbol definiert den Anfang der Zeichenreihenfolge
Beispiel: Du möchtest nach Worten filtern, die mit “Flug” beginnen:
^Flug.+ ergibt eine Übereinstimmung zu “Flugzeug”, “Flughafen”, “Flugzeit“, aber nicht zu “Abflug” oder “Anflug”. Durch .+ passt es auch nicht zu “Flug“, da danach mindestens ein beliebiges Zeichen stehen muss.
9: $
Das Dollarzeichen definiert das Ende der Zeichenreihenfolge.
Beispiel: Mit .+flug$ erhältst du die umgekehrte Übereinstimmung wie bei Punkt 8. Also alle Keywords, die mit „flug“ enden, wie „Abflug“ oder „Anflug“.
Du kannst z. B. mit dem RegEx .+\.pdf$ nach deinen PDF-Dateien suchen.
10. [ ]
Die eckigen Klammern inkludieren ein beliebiges Zeichen, das sich zwischen ihnen befindet. Mit einem Bindestrich kannst du einen Bereich von Zeichen angeben.
Beispiel: c[aou]p passt auf “cap”, “cop”, “cup”, aber nicht zu “caop”.
Wenn du wissen möchtest, wie Nutzer:innen zwischen 10 und 15 konvertieren, benutzt du den Ausdruck 1[0-5]
11: \d
Diese Zeichenfolge umfasst eine beliebige Zahl zwischen 0-9.
Vorsicht: Bei Regex-Zeichen wird zwischen Groß- und Kleinschreibung unterschieden. Wenn du das d groß schreibst, etwa \D, wird es negiert. Das heißt, es passt auf jedes Zeichen, das NICHT eine Zahl zwischen 0-9 ist. Also Buchstaben, Symbole etc.
Beispiel: Möchtest du nach Keywords filtern, die mindestens eine Zahl enthalten, kannst du mit dem RegEx .*\d.* suchen
12: { }
Die geschwungenen Klammern zeigen an, wie oft ein Zeichen wiederholt werden soll. Sie enthalten entweder eine Zahl, oder zwei durch ein Komma getrennte Zahlen.
Beispiel: Möchtest du nach Keywords filtern, die fünf aufeinanderfolgende Zahlen beinhalten, sieht dein RegEx so aus: .*\d{5}.*
1. Nehmen wir an, du arbeitest bei Obi und möchtest in Sistrix deine Top Keywords nach “Gartenzaun” oder “Vorgartenzaun” filtern. Natürlich möchtest du hier auch den Plural mit einbeziehen.
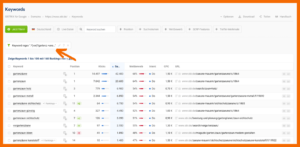
SISTRIX: Keywords mit RegEx filtern
.*(vor)?gartenz.+une?.*
Mit diesem Regex hast du sogar die Schreibweise ohne Umlaute, nämlich “Vorgartenzaeune” und “Gartenzaeune” inkludiert.
2. Im Screaming Frog kannst du das Crawling auf bestimmte Verzeichnisse beschränken. Z. B. kannst du nach deinen Gewinn generierenden Seiten filtern. Bei 121WATT sind es die Verzeichnisse /seminare/ , /kurse/ und /weiterbildung/.
Hierfür ist ein möglicher RegEx: .*/(seminare|kurse|weiterbildung)/.*
→ kein bis beliebig viele Zeichen, dann das Verzeichnis /seminare/ oder /kurse/ oder /weiterbildung/ und anschließend wieder kein bis beliebig viele Zeichen.
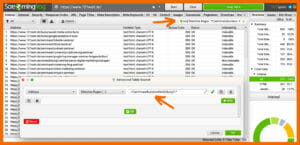
ScreamingFrog: Verwendung von regulären Ausdrücken
3. Du möchtest in einem Bericht nach einer bestimmten Region, nämlich allen Postleitzahlen im Postleitzahlbereich 8 filtern.
Hier ist der richtige RegEx: ^8[\d]{4}$
Das bedeutet, dass nach allen Zahlen gesucht wird, die mit 8 beginnen, gefolgt von 4 Zahlen zwischen 0-9 und dann enden.
Wenn es dir zu mühsam ist, die Regulären Ausdrücke selbst zu erstellen, kannst du natürlich auch KIs wie ChatGPT nutzen. In unserem Beispiel liefert dir ChatGPT den regulären Ausdruck mit Erklärung der einzelnen Zeichen.
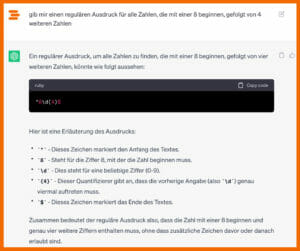
RegEx mit ChatGPT erstellen
Wenn du deinen RegEx testen möchtest, kannst du das ganz einfach mit dem Tool regular expressions 101. Dafür gibst du deinen regulären Ausdruck in das “Regular expression” Feld ein und in das Feld “Test string” darunter zumindest ein paar deiner Zeichenfolgen, die du herausfiltern möchtest. Gib zusätzlich Zeichenfolgen ein, die nur einen Teil der Anforderungen erfüllen. So weißt du, ob du auch wirklich an alles gedacht hast.
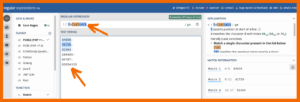
Beispiel 1: Überprüfung eines RegEx mit regex101
In diesem Beispiel siehst du, dass wir definiert haben, wo die Zahl beginnt und wie sie weitergeht, aber nicht, wo sie endet. Das erinnert dich an das $ Zeichen zum Schluss.
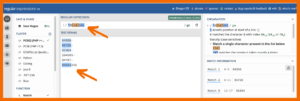
Beispiel 2: Überprüfung eines RegEx mit regex101
Du siehst also, was für ein hilfreiches Tool die Regulären Ausdrücke sind. Mit RegEx kannst du, falls noch nicht geschehen, deine Web-Analyse auf ein neues Level bringen und sie effektiver und effizienter gestalten. Allerdings können Pattern schon mal weitaus komplizierter werden, als in diesem Artikel. Falls du Unterstützung bei der Erstellung benötigst, liefert ChatGPT mit der richtigen Aufgabenstellung zuverlässige Ergebnisse.
Mehr zum Thema Reguläre Ausdrücke inklusive Erklär-Video findest du bei Annielytics.
Dein Feedback hilft uns, unsere Inhalte noch besser zu machen.
Schade! Bitte schreib uns kurz, was dir gefehlt hat – so werden wir besser.

