
Jetzt wird’s technisch: Erst im letzten Newsletter haben wir dir erklärt, wie du E-E-A-T auf deine lokale SEO-Strategie anwendest. Heute wollen wir etwas tiefer gehen und uns ansehen, wie Goolge E-E-A-T überhaupt bewertet und welche... » weiterlesen
Jetzt wird’s technisch: Erst im letzten Newsletter haben wir dir erklärt, wie du E-E-A-T auf deine lokale SEO-Strategie anwendest. Heute wollen wir etwas tiefer gehen und uns ansehen, wie Goolge E-E-A-T überhaupt bewertet und welche Faktoren dafür eine Rolle spielen, vor allem im Bezug auf den Autor bzw. die Autorin. Unsere Quelle ist hier ein Artikel vom Search Engine Land.
Bevor wir loslegen, müssen wir eine ganze Reihe an Begriffen klären, die du für den Artikel kennen und verstehen solltest. Hier findest du unser kleines Glossar.
Entität: Google beschreibt eine Entität als einzigartiges Ding oder Konzept, das sich trennscharf und gut definiert von anderen Entitäten unterscheidet. Eine Entität muss nicht zwingend ein Objekt oder eine Person sein, sondern es kann sich auch um einen Ort, eine Idee, eine Farbe oder ein Datum handeln. Die treffendste Übersetzung für Entität wäre hier wohl „Einheit“. Entitäten werden manchmal mit Suchbegriffen verwechselt, allerdings unterscheiden sie sich.
Bei Neil Partel haben wir ein passendes Beispiel gefunden: Apple
Gibst du Apple in die Google Suche ein, meinst du damit entweder das Obst oder die Marke. Obwohl der Suchbegriff der gleiche ist, handelt es sich hier um zwei unterschiedliche Entitäten. Bei der Entität schwingen immer noch andere Eigenschaften mit (die im Content zu finden sein müssen), welche die Entitäten voneinander differenzieren. Wenn du mehr über entitätenbasierte SEO erfahren möchtest, empfehlen wir dir ebenfalls den Artikel von Neil Partel.
Autor: Der Autor ist die Person, welche den Text geschrieben hat.
Herausgeber: Der Herausgeber ist in der Regel das Unternehmen, das hinter einer Website steht. Gegebenenfalls ist es auch die Website selbst.
Knowledge Graph: Der Google Knowledge Graph ist eine Erweiterung der Google Suche. Er wurde 2012 eingeführt und besteht aus Widget-ähnlichen Kästen, welche Informationen zu einer bestimmten Entität enthalten. Du kennst sie bestimmt, beispielsweise als Kasten, der rechts neben den regulären Suchergebnissen auftaucht und Informationen zu deinem Suchbegriff enthält.
Knowledge Vault: Der Google Knowledge Vault ist der Versuch von Google, eine riesige Wissensdatenbank aufzubauen. Dabei wendet Google maschinelles Lernen ein, um ungeordnete Daten zu ordnen und in dem Vault (oder auch „Wissensspeicher“) zu organisieren. Der Vault dient als Grundlage für verschiedene Google-Dienste, beispielsweise dem Google Assistenten oder den Knowledge Graphs. Auch Beziehungen zwischen den Informationen im Knowledge Vault werden festgehalten.
Vektor: Ein Vektor ist ein mathematisches Konzept und kann ein beliebiges Objekt repräsentieren. Er besteht aus einer geordneten Reihe von Zahlen, die auch als Koordinaten bezeichnet werden. Jede Koordinate steht dabei für eine Eigenschaft des Objekts. Im Kontext dieses Artikels kann jede Entität durch einen Vektor beschrieben werden. Vektoren machen die verschiedenen Entitäten miteinander vergleichbar.
Embedding: Embedding, oder Einbettung, ist ein Begriff aus dem Machine Learning. Einfach ausgedrückt: Eine Einbettung stellt komplexe Daten (z. B. Texte, Audio, Videos etc.) so dar, dass Maschinen sie auslösen können. Dabei „übersetzt“ die Einbettung Objekte und Datenpunkte in einen Vektor (= in eine Reihe von verschiedenen Zahlen). Machine-Learning-Modelle erlernen diese Einbettungen und können damit große Datenmengen verarbeiten, Daten klassifizieren, Ähnlichkeiten zwischen den Vektoren suchen und Empfehlungen durchführen.
Bei dem bekannten Modell Word2Vec beispielsweise werden Wörter so in einen Vektorraum eingebettet, dass ähnliche Wörter auch durch ähnliche Vektoren repräsentiert werden. Wenn beispielsweise die Einbettung für „König“ der für „Königin“ ähnelt, kann die Maschine erkennen, dass diese Wörter in einer Beziehung zueinander stehen.
Part-of-Speech-Tagging (POS): Beim POS-Tagging wird den verschiedenen Wörtern eines Textes jeweils automatisiert eine Wortart zugeordnet (z. B. Nomen, Verb, Adverb, Adjektiv, Konjunktion etc.). POS-Tagging ist eine Teildisziplin der Computerlinguistik.
Das E-E-A-T-Konzept soll die Qualität der Suchergebnisse auf der SERP für die User:innen verbessern. Dabei wird den Quellen der Inhalte eine besondere Relevanz zugeschrieben, allen voran dem Autor eines Artikels.
E-E-A-T ist EINER von mehreren unabhängigen Rankingfaktoren. E-E-A-T- bewertet dabei keine einzelnen Inhalte (das ist ein anderer Rankingfaktor), sondern betrachtet größere, thematische Einheiten einer Domain. Bist du beispielsweise Experte oder Expertin für Skitouren, aber gleichzeitig auch für Wandertouren im Sommer, so ist es wahrscheinlich, dass Google dich zweimal nach E-E-A-T bewertet: einmal für den Wintersport und einmal für die Touren im Sommer.
Zum besseren Verständnis haben wir dir hier die verschiedenen Ebenen aufgezeigt, welche Google bewerten kann. In diesem Artikel beschäftigen wir uns mit dem Entity-Level.
Dokumenten-Ebene
Domain-Ebene
Entitäts-Level
Bereits lange bevor E-E-A-T eingeführt wurde, hat Google versucht, die Bewertungen von Inhalten in das Ranking einfließen zu lassen. Beispielsweise hat das Vince-Update Inhalten von (bekannten) Marken einen Rankingvorteil verschafft. Außerdem sollten verschiedene Projekte wie Google Knol oder Google+ Faktoren für die Bewertung von Autor-Bewertungen festlegen und Daten dazu sammeln. In den letzten 20 Jahren hat Google verschiedene Patente angemeldet, die direkt oder indirekt mit Content-Plattformen wie Knol oder Social-Media-Plattformen wie Google+ zusammenhängen und mit deren Daten die Autorenbewertung vereinfachen sollen.
Warum ist die Qualität der Inhalte so wichtig für Google?
Der erste und offensichtliche Grund ist, dass Google seinen Nutzerinnen und Nutzern die bestmöglichen Suchergebnisse liefern möchte und damit die Nutzerzufriedenheit und die Wiederkehrrate hoch halten will. Hochwertiger Content ist aktuell wichtiger denn je, da bereits jetzt viele von KI-erstellte, minderwertige Inhalte im Netz kursieren, die Google nicht unbedingt auf den vorderen Suchergebnissen platzieren möchte. Durch die Bewertung des Autors bzw. der Autorin, kann Google die Anzahl der von KI erstellten Suchergebnisse eindämmen.
Der zweite, weniger offensichtliche Grund ist die Rechenleistung, die Google für das Crawling von Inhalten verwendet. E-E-A-T hilft Google beim Ranking, indem es die verschiedenen Entitäten wie Herausgeber und Autor sowie die gesamte Domain in einem größeren Kontext betrachtet, ohne jede einzelne Seite crawlen zu müssen. Google evaluiert dann, ob es sich um eine qualitativ hochwertige Domain handelt oder nicht und kann dementsprechend Crawlbudget vergeben. Diese Methode kann auch angewendet werden, um komplette Content-Gruppen aus dem Index auszuschließen.
Wie kann Google Autoren identifizieren?
Autoren gehören zur Entitäten-Gruppe „Personen“. Google unterscheidet dabei zwischen Personen, die bereits ordentlich erfasst wurden und beispielsweise im Knowledge Graph dargestellt werden können, und aktuell unbekannten Personen, die lediglich als Information im Knowledge Vault existieren. Mit Hilfe von Machine Learning und Sprachmodellen kann Google einen spezifischen Autor identifizieren und ihn als Entität im Knowledge Graph anlegen. Dieser Prozess heißt „Named Entity Recognition“ (NER) und ist ein untergeordneter Prozess im NLP (Natural Language Processing).
Vereinfacht ausgedrückt, erkennt NER Wörter anhand verschiedener linguistischer Muster und ordnet jedes Wort aus einem Text einer bestimmten Gruppe zu. Dann wird jedes Wort in einen Vektor übersetzt. Anschließend wird via Part-of-Speech-Tagging jedem Vektor eine grammatikalische Klasse zugeordnet. Subjekte werden so zu Haupt-Entitäten, Objekte zu sekundären Entitäten und Verben und Präpositionen stellen die Verbindungen zwischen den verschiedenen Entitäten her. Eine Entität kann sowohl als Knotenvektor, als auch als eingebettete Entität erscheinen.
Zum besseren Verständnis haben wir dir hier den Prozess vom Text bis hin zur Entität dargestellt:
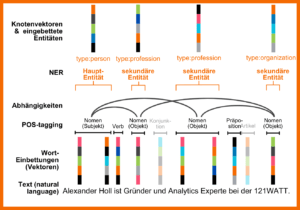
Vom Text zur Entität – der Vorgang von Natural Language Processing (NLP)
NLP kann (mit Hilfe von NER) also Entitäten identifizieren und ihre Beziehungen zueinander erkennen, indem sie die verschiedenen Entitäten als Vektoren darstellt. Über die sogenannte Einbettung werden die verschiedenen Vektoren anschließend in einem mathematischen Raum zusammengeführt, sodass die Maschine Unterschiede und Gemeinsamkeiten zwischen den einzelnen Vektoren erkennen kann.
Soweit verstanden? Dann machen wir weiter.
Nun gibt es nicht nur Vektoren für die Entität des Autors, auch komplette Inhalte können als Vektor dargestellt werden. Wenn beide über eine Einbettung im selben Raum dargestellt werden, kann die Maschine beide Vektoren miteinander vergleichen. Da ein Vektor ein räumliches Element ist, entscheidet der Abstand zwischen den beiden Vektoren darüber, wie wahrscheinlich es ist, dass ein Inhalt von einem spezifischen Autor verfasst wurde. Anders gesagt: Die Maschine matched die Vektoren miteinander und je mehr Übereinstimmungen es gibt, desto sicherer kann die Maschine sein, dass der im Vektor dargestellte Autor den dargestellten Inhalt verfasst hat. Mit dieser Technik kann Google übrigens auch Inhalte miteinander vergleichen und so z. B. Duplicate Content identifizieren.
Zur Veranschaulichung haben wir dir auch das in einer Grafik festgehalten:

Mit dieser Technik kann verhindert werden, dass ein Inhalt der falschen Autorin zugewiesen wird. Das Ganze klingt übrigens gerade technischer, als es eigentlich ist. Der offensichtlichste Faktor, auf den die Vektoren verglichen werden können, ist beispielsweise, ob die Autorinnen-Entität mit dem Namen der Autorin übereinstimmt, die in einem Artikel als Autorin angegeben wurde.
Dir ist das ganze immer noch zu abstrakt? Wir haben ein einfaches Beispiel erarbeitet, an dem wir dir erklären möchten, wie Google mit Vektoren arbeitet. Dazu nutzt Google das System “Word2Vec”, welches Wörter mithilfe von Einbettungen in Vektoren übersetzt, um diese für die Maschine lesbar und vergleichbar zu machen.
Schritt 1: Wir haben eine Liste von Tieren erstellt und verschiedene Eigenschaften definiert. Anschließend haben wir mit Hilfe von ChatGPT die Ausprägung jeder Eigenschaft für jedes Tier auf einer Skala von -1 bis +1 festgelegt.
Die Tiere entsprechen dabei verschiedenen Entitäten.
Die Ausprägungen der Eigenschaften sind Zahlen und bilden gemeinsam einen Vektor.
ChatGPT ist in dem Fall die Einbettung, welche die Eigenschaften und Tiere in jeweils einen Vektor übersetzt.
Prompt 1: Sortiere die Tiere französische Bulldogge, Delphin, Anaconda, Wildschwein, Blauwal und Salzwasserkrokodil auf Basis der Eigenschaft “intelligent”.
Prompt 2: Setze diese Reihenfolge in numerische Werte von -1 bis +1 um.
Wiederhole nun das Vorgehen aus Prompt 2 für alle Eigenschaften, die du betrachten möchtest. Anschließend erhältst du eine Tabelle mit verschiedenen Ausprägungen der Eigenschaften der Tiere. Jedes Tier wird nun durch einen Vektor repräsentiert, der aus sechs Zahlen besteht.

Schritt 2: Nun sollen die einzelnen Vektoren untereinander verglichen werden. Wählst du nur zwei der Eigenschaften aus, handelt es sich um zweidimensionale Vektoren, die du beispielsweise über ein Diagramm in Google Sheets darstellen kannst.

Die Vektoren werden hier durch Kreise dargestellt. Du kannst erkennen, dass sich die französische Bulldogge und das Wildschwein sehr ähnlich sind, zumindest was die Eigenschaften “sozial” und “intelligent” angeht. Die Anaconda und der Delphin liegen am weitesten auseinander und sind somit am wenigsten vergleichbar.
Schritt 3: Wenn du mehr als zwei Eigenschaften miteinander vergleichen möchtest, bräuchtest du ein mehrdimensionales Diagramm, welches sich zumindest mit Google Sheets nicht umsetzen lässt.
Wir haben ChatGPT gefragt, ob es auf Basis der gesamten Tabelle die Ähnlichkeiten zwischen den einzelnen Tieren ausrechnen kann. Dazu nutzt ChatGPT eine Cosinus-Funktion, wie sie auch in Word2Vec Anwendung findet.
Prompt 6: Berechne aufgrund der oben dargestellten Tabelle, wie ähnlich sich die verschiedenen Tiere auf Basis der Eigenschaften sind.
Als Ergebnis erhalten wir diese Tabelle:

Je größer die Zahl, desto ähnlicher sind die Tiere (= Vektoren). Die meiste Ähnlichkeit besteht laut diesem Modell also zwischen der französischen Bulldogge und dem Delphin. Die wenigste Ähnlichkeit weisen der Delphin und die Anaconda auf.
Damit Google eine Autorinnen-Entität erstellen kann, braucht es Informationen über die Autorin. Diese bezieht Google aus folgenden Quellen:
Googlest du eine Person, die bereits als Named Entity bei Google vorhanden ist, bekommst du alle Informationen, die Google über die besagte Person gesammelt hat, in einem Knowledge Graph ausgespielt. Das können Angaben zur Person sein, aber beispielsweise auch Links zu Social-Media-Profilen oder Publikationen der Person.
Im Prinzip musst du dir nur merken, dass Google zur Identifikation eines Autors oder einer Autorin nicht nur den Namen verwendet, da dieser nicht eindeutig ist. Weitere Signale sind beispielsweise:
Google hat verschiedene Patente angemeldet, die ihnen bei der Identifizierung und Bewertung von Autoren helfen. Leider ist nicht abschließend geklärt, ob alle Techniken zum Einsatz kommen, ob es nur ein paar sind oder ob es sich z. B. nur um eine handelt. Einige Patente überschneiden sich auch und oftmals sind die wirklichen Unterschiede für uns Laien nicht zu erkennen.
Autoren Vektoren
Google hat dieses Patent 2016 angemeldet. Es ist aktuell allerdings nur in den USA gültig, was darauf schließen lässt, dass diese Methode nicht weltweit in der Suche eingesetzt wird. Das Patent beschreibt, dass Autoren von Vektoren repräsentiert werden, die auf Trainingsdaten basieren. Ein Vektor wird durch eindeutige Parameter identifiziert, die auf dem typischen Schreibstil und der Wortwahl des Autors basieren. Auf diese Weise können neue Inhalte dem Autor zugeschrieben werden und Autoren mit ähnlichen Stilen können in Clustern zusammengefasst werden. Das Content-Ranking kann dann für einen oder mehrere Autoren basierend auf dem vorherigen Nutzungsverhalten eines Nutzers oder einer Nutzerin angepasst werden. Hast du beispielsweise schon oft Inhalte von Autor XY konsumiert, so ist es wahrscheinlich, dass du vermehrt Inhalte des Autors XY oder ähnlichen Autoren ausgespielt bekommst. Denke aber daran, dass diese Technologie aktuell nicht (weltweit) genutzt wird.
Reputation der Autorin
Dieses Patent wurde 2008 mit einer Laufzeit bis 2029 von Google angemeldet. Ursprünglich wurde die Technologie im bereits ausgelaufenen Google Knol Projekt eingesetzt. Zwar wurde das Knol Projekt 2012 eingestellt, das Patent wurde aber unter dem neuen Namen „Monetarisierung von Online Content“ erneut unterzeichnet. Die Technologie errechnet einen sogenannten „Reputation Score“. Dafür werden folgende Faktoren mit einbezogen:
Eine Autorin kann mehrere Reputation Scores haben, je nach Thema. Außerdem kann sie verschiedene Aliasse für verschiedene Fachbereiche verwenden. Das bedeutet nicht, dass sie unter verschiedenen Namen auftreten soll, sondern, dass sie für verschiedene Fachbereiche verschiedene Autorinnen-Beschreibungen haben kann. Diese kann dann die wichtigen Stationen in ihrem Lebenslauf beschreiben, welche für das entsprechende Themengebiet relevant sind.
Agent Rank
Dieses Patent wurde 2006 beschlossen und gilt mindestens bis 2026. Da es weltweit registriert wurde, ist es wahrscheinlich, dass es auch weltweit in der Google Suche Anwendung findet.
Die generelle Idee dahinter ist, dass eine Seite nicht auf Basis des gesamten Inhalts auf einmal bewertet wird, sondern anhand kleinerer Einheiten, die sich auf der Seite befinden. Dem Konzept liegt die Annahme zu Grunde, dass der Inhalt auf einer Seite nicht zwingend aus einer Feder stammen muss, sondern dass mehrere Autoren daran beteiligt sein können.
Die Technologie schreibt digitale Inhalte einem bestimmten Autor oder Herausgeber (= Agent) zu. Aus dem entsprechenden Inhalt und dessen Backlinks ergibt sich dann der Agent Rank, der dem bestimmten Autor zugeschrieben wird. Der Agent Rank ist unabhängig vom Suchintent der Nutzer:innen und bezieht sich immer auf eine Suchanfrage, ein Suchanfragen-Cluster oder gesamte Themengebiete.
Der Agent Rank kann auch relativ zu Suchbegriffen oder Kategorien von Suchbegriffen berechnet werden. Beispiel: Suchbegriffe können in verschiedene Kategorien eingeteilt werden (z. B. Sport vs. medizinische Fachgebiete). Ein Agent kann dann für jedes einzelne Gebiet einen unterschiedlichen Agent Rank haben.
Glaubwürdigkeit einer Autorin von Online Inhalten
Dieses Google Patent wurde 2008 unterschrieben und gilt mindestens bis 2029, aber aktuell nur in den USA. Ähnlich wie das Patent der Reputationsbewertung ist es direkt mit der Suche bei Google verbunden.
Das Patent beschreibt verschiedene Faktoren, die von einem Algorithmus ausgewertet werden, um die Glaubwürdigkeit einer Autorin zu ermitteln. Es beschreibt, wie die Suchmaschine beim Ranking von Dokumenten vom Credibility Score und dem Reputation Score beeinflusst wird. Dabei kann eine Autorin verschiedene Scores haben, je nachdem in wie vielen Fachbereichen sie Inhalte veröffentlicht. Der Reputation Score einer Autorin ist unabhängig vom Herausgeber (= Webseite /Unternehmen). Auch verweisende Links werden hier in das Ranking mit einbezogen und können den Reputaion Score einer Autorin beeinflussen. Für den Reputation Score werden folgende Signale verwendet:
Weitere Interessante Infos über den Reputation Score von diesem Patent:
Neben dem Reputation Score bekommt jede Autorin auch einen Glaubwürdigkeits-Faktor (= Credibility Score). Dieser wird von folgenden Faktoren beeinflusst:
Systeme und Methoden für das Re-Ranking von bereits rankenden Suchergebnissen
Dieses Google Patent wurde 2013 beschlossen und gilt bis mindestens 2033. Es wurde weltweit registriert, was bedeutet, dass es vermutlich überall in der Google Suche angewendet wird.
Heruntergebrochen beschreibt dieses Patent, das Suchmaschinen zusätzlich zu den Referenzen der Inhalte eines Autors, auch den Anteil, den der Autor zu einem thematischen Dokumentenkorpus in einem Autorenranking beitragen kann.
Beispiel: Wenn es nur 3 Artikel zu einem Thema gibt und ich 2 schreibe, ist das sehr gut. Gibt es 3.000.000 Artikel zu einem Thema und ich schreibe 2, ist das kein gutes Signal.
Außerdem spielt scheinbar auch das sogenannte Zitatscoring eine Rolle. Dabei wird auf die Anzahl der Referenzen (= Links) geachtet, welche auf den Text des Autors verweisen. Das Patent soll unter anderem Plagiate und Nachahmer erkennen und deren Inhalte in ihrem Ranking herabstufen. Prinzipiell kann es aber auch dazu genutzt werden, Autoren generell zu bewerten.
In diesem Artikel hast du verschiedene Faktoren kennengelernt, die zur Bewertung von Autoren und Autorinnen dienen. Die Technik dafür kommt von Google, du musst lediglich wissen, wie du sie dir zu Nutzen machst. Folgendes kannst du also tun, damit du als Autor:in gut bewertet wirst:
Zusätzlich zu den in den oben genannten Patenten für die Bewertung von Autoren, findest du hier weitere Faktoren, die sehr wahrscheinlich eine Rolle spielen:
Besonders mit der Weiterentwicklung von künstlicher Intelligenz wird E-E-A-T in Zukunft eine immer wichtigere Rolle spielen. Vermutlich werden die Faktoren irgendwann genauso wichtig sein wie die Optimierung der Inhalte an sich.
Alles zu den Patenten und den Techniken kannst du beim Search Engine Land nachlesen.
Dein Feedback hilft uns, unsere Inhalte noch besser zu machen.

