

KI und GEO Glossar – diese Begriffe musst du kennen (GEO / LLMO Teil 1)
Keine Artikel mehr verpassen? Jetzt Newsletter abonnieren »
In unserer Artikelserie zum Thema Large Language Model Optimization stellen wir dir alle zwei Wochen einen neues Aspekt der LLMO bzw. Generative Engine Optimization vor. Heute starten wir mit einem KI-Glossar, in dem wir die wichtigsten Begriffe rum um die Themen KI, GEO und LLMO einmal klären.
Adversarial Prompting: Eine Technik, um KI-Modelle durch absichtlich manipulative Eingaben in die Irre zu führen. So sollen Regeln umgangen, geheime Informationen preisgegeben oder schädliche Inhalte erzeugt werden. Erfahre mehr über Adversarial Prompting.
Agenten: KI-Systeme, die Aufgaben selbstständig ausführen, indem sie Informationen verarbeiten, Handlungen planen und Entscheidungen treffen. Anders als herkömmliche KI-Modelle reagieren sie nicht nur auf Eingaben, sondern können selbständig Zwischenschritte planen und auf externe Daten zurückgreifen. Ein Beispiel dafür ist das Microsoft Copilot Studio. Erfahre mehr über Agenten.
AI Mode: Ein spezieller Google-Modus, in dem Nutzende direkt in der Google Suche mit dem KI-Modell chatten und Rückfragen zu ihren Anfragen stellen können. In Europa ist er noch nicht verfügbar. Erfahre mehr über den AI Mode.
AI Overviews: KI-generierte Zusammenfassungen, die direkt auf der Google SERP angezeigt werden. Sie fassen relevante Informationen aus mehreren Quellen in kurzer Form zusammen, ohne dass Nutzende alle einzelnen Seiten besuchen müssen. Erfahre mehr über AI Overviews.
Artificial General Intelligence (AGI): Wird auch „Strong AI“ (starke KI) oder „Full AI“ genannt und bezeichnet eine KI, die darauf ausgelegt ist, jede intellektuelle Aufgabe ausführen zu können, die auch ein Mensch ausführen kann. Sie ist nicht auf spezielle Use Cases limitiert. Erfahre mehr über AGI.
Artificial Intelligence (AI): Auch „Künstliche Intelligenz (KI)“, ist ein Teilgebiet der Informatik, das sich mit der Entwicklung von Systemen beschäftigt, die menschenähnliches Denken und Verhalten nachahmen können. Erfahre mehr über AI.
Attention Mechanismen: Eine Technik, bei der die KI den wichtigen Teil der Eingabe gezielt stärker beachtet als die anderen Elemente. Dadurch werden Antworten präziser und die Eingabe kann besser verstanden werden, vor allem wenn der Inhalt komplex oder mehrdeutig ist. Erfahre mehr über Attention Mechanismen.
Accuracy: Eine Kennzahl zur Bewertung der Genauigkeit der Modellleistung. Sie beschreibt den Anteil aller Vorhersagen, die richtig waren. Beispiel: Von 100 E-Mails erkennt die KI bei 90 E-Mails richtig, ob es sich um Spam handelt oder nicht ➡️ Accuracy = 90 %. Erfahre mehr über Accuracy.
Backpropagation: Ein Trainingsalgorithmus, bei dem die KI ihre eigenen Fehler beim Lernen korrigiert. Bei falschen Angaben geht die KI Schritt für Schritt zurück, findet den Fehler und passt anschließend ihre internen Einstellungen an, damit der Fehler nicht nochmal passiert. Erfahre mehr über Backpropagation.
Bias: Systematische Verzerrungen in den Ausgaben eines Modells aufgrund der Trainingsdaten. Erfahre mehr über Bias.
Chain-of-Thought: Eine Prompting Technik, bei der das Modell nicht auf einmal, sondern schrittweise zu einer Lösung geführt wird, ähnlich einem Denkprozess. Erfahre mehr über Chain-of-Thought.
Chatbot: Ein text- oder sprachbasiertes Dialogsystem, das mit Nutzenden kommunizieren kann. Sie werden häufig für den Kundensupport auf Websites eingesetzt, um Nutzenden rund um die Uhr eine schnelle Hilfestellung zu gewährleisten. Erfahre mehr über Chatbots.
CustomGPT: Ein maßgeschneiderter digitaler Assistent innerhalb von ChatGPT, der durch den Nutzer oder die Nutzerin auf spezielle Inhalte, Prozesse und Ziele zugeschnitten wurde. Gleiche Funktionen gibt es zum Beispiel auch bei Gemini (Gems) oder Claude (Artefakte). Erfahre mehr über CustomGPTs.
Decoder: Wandelt die vom KI-System erstellte Darstellung um, um Schritt für Schritt eine Ausgabe zu erzeugen, die von Menschen konsumiert werden kann (bspw. Text). Erfahre mehr über Decoder.
Deep Learning (DL): Ein Teilbereich des Machine Learnings (ML), der neuronale Netzwerke mit vielen Schichten (Deep Neural Networks) nutzt, um große Datenmengen zu verarbeiten und komplexe Probleme zu lösen. Erfahre mehr über Deep Learning.
Embeddings: Die Darstellung von Wörtern, Sätzen oder ganzen Texten in Vektoren. Damit kann die semantische Bedeutung von Inhalten mathematisch dargestellt und mit anderen abgeglichen werden. Wörter mit ähnlicher Bedeutung können identifiziert werden, da sie im Vektorraum nah beieinander liegen. Dieser Vorgang wird zur Erkennung von Zusammenhängen bei der Suche, beim Clustering oder in Empfehlungssystemen genutzt. Beispiel: Die Wörter „Auto“ und „Fahrzeug“ liegen im Vektorraum sehr nah beieinander, obwohl die Wörter sich ansich nicht ähneln. Erfahre mehr über Embeddings.
Du will im Detail GEO lernen? Dann ist vielleicht unsere GEO Schulung , das GEO Seminar Fortgeschritten oder unsere zertifizierte GEO-Weiterbildung mit ~10 Seminartagen für dich relevant.
Encoder: Wandelt im KI-System den eingegebenen Text in eine interne, strukturierte Darstellung um, sodass das System ihn anschließend verarbeiten kann. Erfahre mehr über Encoder.
Entität: Beschreibt ein eindeutig identifizierbares Objekt, Datum oder Konzept in einer Suchanfrage, das in einem spezifischen Kontext betrachtet werden muss. Im Prinzip kann nahezu alles eine Entität darstellen, etwa Personen, Dinge, Orte, Datenpunkte, Ereignisse oder auch abstrakte Konzepte.
Beispiele für Entitäten:
- Personen: Barak Obama (44. Präsident der USA), Adele (britische Sängerin & Songwriterin)
- Dinge: iPhone (Smartphone-Reihe von Apple), Lego (beliebtes Konstruktionsspielzeug)
- Orte: Santorini (Griechische Insel in der Ägäis), Sydney Opera House (Wahrzeichen in Australien)
- Datenpunkte: ISBN 978-3-16-148410-0 (eindeutige Buchkennummer), Flugnummer LH456 – Lufthansa-Flug Frankfurt–Los Angeles
- Ereignisse: Fall der Berliner Mauer 1989 (historisches politisches Ereignis), Fußball-WM 2014 (Sieg der deutschen Nationalmannschaft in Brasilien)
- abstrakte Konzepte: Gerechtigkeit (philosophisches und rechtliches Prinzip), Freiheit (grundlegendes Menschenrecht)
Jeder Entität können Attribute mit zusätzlichen Informationen zugeschrieben werden, bei Personen z. B. Geburtstag, Hobbies oder Nationalität. Erfahre mehr über Entitäten.
EU AI Act: Die Gesetzgebung der EU zur Regulierung von KI in Europa. Erfahre mehr über den EU AI Act.
Evaluation Metrics: Metriken zur quantitativen Bewertung der Leistung von Modellen (z. B. Accuracy, Precision, Recall und F1-Score). Erfahre mehr über Evaluation Metrics.
Explainability (Interpretierbarkeit): Das Maß, in dem nachvollziehbar ist, wie ein Modell zu seinen Entscheidungen kommt. Erfahre mehr über die Explainability.
Explainable AI (XAI): Techniken zur Erklärung der Entscheidungsprozesse von KI. Erfahre mehr über XAI.
Fairness: Die Eigenschaft eines Modells, keine Gruppen systematisch zu benachteiligen. Erfahre mehr über Fairness.
Feedforward Neural Network: Ein einfaches neuronales Netz, bei dem Daten nur in eine Richtung fließen. Erfahre mehr über Feedforward Neural Networks.
Few-Shot Learning / Zero-Shot Learning: Modelle lösen Aufgaben mit wenigen (few-shot) oder keinen Beispielen (zero-shot) durch Transferwissen. Erfahre mehr über Few-Shot Learning.
Finetuning: Weiteres Training eines Modells auf spezifischen Daten, um es auf bestimmte Aufgaben zu spezialisieren. Erfahre mehr über Finetuning.
Frequency-Penalty: Reduziert Wiederholungen, indem die Wahrscheinlichkeit von häufig verwendeten Wörtern verringert wird. Erfahre mehr über die Frequency Penalty.
F1-Score: Die Kennzahl zur Darstellung des harmonischen Mittels von Precision und Recall innerhalb eines Modells. Sie gibt an, wie genau ein Modell ist, wenn sowohl die Genauigkeit innerhalb der gefundenen Positive als auch die Vollständigkeit wichtig sind ➡️ F1 = 2 x ((PrecisionxRecall) / (Precision+Recall)). Erfahre mehr über den F1-Score.
Generative AI (generative KI): Erzeugt auf Grundlage historischer Daten etwas bisher nicht Dagewesenes. Erfahre mehr über GenAI.
Generative AI Optimization (GAIO): Methoden, um generative KI-Systeme gezielt zu verbessern, etwa in der Qualität ihrer Antworten, in der Effizienz ihrer Berechnungen oder in der Genauigkeit der Inhalte. Dazu gehören Feintuning, gezieltes Prompt-Design und die Integration zusätzlicher Wissensquellen. Erfahre mehr über GAIO.
Generative Engine Optimization (GEO): Die Optimierung von Inhalten, damit sie von KI-gesteuerten Such- oder Antwortsystemen gefunden, verstanden und in generierten Antworten verwendet werden können. Erfahre mehr über GEO.
Du willst mehr wissen zum Thema AI-Overviews / Generative Engine Optimization /LLMO wissen? Dann ist vielleicht unser GEO Seminar für dich interessant.
Generative Pretrained Transformer (GPT): Ein KI-Sprachmodell, das darauf trainiert ist, eigenständig Texte zu erstellen, vervollständigen oder zu beantworten. Dabei erzeugt es den Text Wort für Wort, indem es jedes Mal das nächste Wahrscheinliche Wort vorhersagt, basierend auf allem, was es zuvor gesehen hat. Erfahre mehr über GPTs.
Gewichte: Zahlenwerte in einem KI-Modell, mit denen das Modell steuert, wie stark bestimmte Eingaben das Ergebnis beeinflussen. Je besser die Gewichte eingestellt sind, desto besser erkennt ein Modell Muster in den Daten und kann sie auf neue Situationen anwenden. Erfahre mehr über Gewichtung bei KI-Modellen.
Gradient Descent: Ein Optimierungsverfahren, bei dem KI-Modelle während des Trainings ihre internen Einstellungen (Gewichte) so anpassen, dass sie bessere Vorhersagen machen. Erfahre mehr über den Gradient Descent.
Halluzination: Falsche, aber plausibel klingende Aussagen eines Sprachmodells. Erfahre mehr über Halluzinationen.
Haystack: Ein Open-Source-Framework für NLP mit Fokus auf Frage-Antwort-Systeme. Erfahre mehr über Haystack.
Human-in-the-Loop (HITL): Die Integration menschlicher Rückmeldungen zur Qualitätssicherung. Erfahre mehr über HITL.
Inference: Der Vorgang, bei dem ein trainiertes Modell Vorhersagen oder Texte erzeugt. Anders gesagt, es ist der Vorgang, der passiert, nachdem du eine Eingabe im KI-Modell gemacht hast. Erfahre mehr über Inference.
Inference Latency: Die Zeit, die ein Modell benötigt, um auf eine Anfrage zu antworten. Erfahre mehr über Inference Latency.
Jailbreaking: Der absichtliche Versuch, Beschränkungen oder Sicherheitsvorgaben von KI-Modellen zu umgehen, um Inhalte zu erzeugen, die das Modell normalerweise nicht erzeugen würde, z. B. gefährliche Anleitungen, beleidigende Sprache oder vertrauliche Informationen. Der Angriff wird kreativ verpackt, etwa durch die Bitte, in einer fiktiven Geschichte zu Antworten oder den Standpunkt einer bestimmten Rolle einzunehmen. Erfahre mehr über Jailbreaking.
KI-Ethik: Ein Bereich, der sich mit den moralischen Fragen zu KI und zur Nutzung von KI beschäftigt. Erfahre mehr über KI-Ethik.
Knowledge Graph: Eine strukturierte Datenbank, die Informationen in Form von Knoten (Entitäten wie Personen, Orte oder Begriffe) speichert. Es ermöglicht KI-Systemen, Zusammenhänge zwischen Informationen zu verstehen und gezielt darauf zuzugreifen. Erfahre mehr über den Knowledge Graph.
Kontextfenster (Context Window): Die maximale Anzahl an Tokens, die ein Modell gleichzeitig verarbeiten kann. Erfahre mehr über das Kontextfenster.
Künstliche Neuronale Netze (KNN): Rechenmodelle innerhalb der KI, die grob an die Funktionsweise des menschlichen Gehirns angelehnt sind. Sie bestehen aus vielen einzelnen „Neuronen“, die in Schichten angeordnet sind. Jedes Neuron verarbeitet Eingaben, gewichtet sie unterschiedlich und gibt das Ergebnis an die jeweils nächste Schicht weiter. Durch Training kann die Gewichtung beeinflusst werden. Erfahre mehr über KNNs.
LangChain: Ein Framework zur Entwicklung komplexer KI-Anwendungen mit LLMs. Erfahre mehr über LangChain.
Large Language Model (LLM): Ein sehr großes Sprachmodell, das auf umfangreichen Textdaten trainiert ist und komplexe Sprachaufgaben ausführen kann. Erfahre mehr über LLMs.
Large Language Model Optimization (LLMO): Die gezielte Optimierung von Inhalten, damit sie in den Antworten von KI-Sprachmodellen wie ChatGPT, Google Gemini oder Claude berücksichtigt werden.
Achtung: Auch „Large Language Model Operations“ wird mit LLMO abgekürzt. Dabei handelt es sich aber einfach um alle Prozesse, Werkzeuge und Methoden, die nötig sind, um große Sprachmodelle (LLMs) zuverlässig, effizient und sicher zu betreiben. Erfahre mehr über LLMO.
Large Multimodal Model (LMM): Ein KI-Modell, das in der Lage ist, Informationen aus verschiedenen Datenformen und -quellen zu verstehen und zu generieren, beispielsweise Text, Bilder, Audio und Video. Erfahre mehr über LMMs.
Load Balancing: Die Verteilung von Anfragen auf verschiedene Modellinstanzen zur Lastverteilung. Erfahre mehr über Load Balancing.
Loss Function: Eine mathematische Funktion, die den Fehler eines Modells misst. Erfahre mehr über die Loss Function.
Machine Learning (ML): Der Ansatz innerhalb der KI, bei dem Systeme aus Daten lernen und eigene Schlüsse ziehen, ohne explizit dafür programmiert zu sein. Erfahre mehr über ML.
Modell: Ein mathematisches Konstrukt, das auf Grundlage von Trainingsdaten Vorhersagen oder Entscheidungen trifft. Erfahre mehr über Modelle.
Modellgröße (Parameteranzahl): Beschreibt, wie viele Parameter ein KI-Modell hat. Je größer das Modell (je mehr Parameter es hat), desto mehr Wissen und Daten kann es speichern und verarbeiten. Bei steigender Kapazität werden aber auch mehr Rechenleistung und Speicherplatz nötig, was die Kosten für das Modell steigen lässt. Kleine Modelle sind schneller und günstiger, große Modelle können komplexere Aufgaben bewältigen und liefern i. d. R. bessere Ergebnisse. Erfahre mehr über die Modellgröße.
Model Deployment: Der Prozess, bei dem ein trainiertes Modell in eine produktive Umgebung überführt wird. Erfahre mehr über Model Deployment.
Model Distillation: Die Komprimierung eines großen Modells in eine kleinere Version mit ähnlicher Performance. Erfahre mehr über Model Distillation.
Natural Language Processing (NLP): Ermöglicht es Computern, natürliche, menschliche Sprache zu verstehen, egal ob in Schrift- oder in Audioform. Mithilfe von KI werden die Eingaben aus der realen Welt dann verarbeitet und so dargestellt, dass ein Computer sie verstehen kann. Erfahre mehr über NLP.
Open Source Modelle: Frei zugängliche KI-Modelle, die öffentlich genutzt und verändert werden dürfen und können. Erfahre mehr über Open Source.
Open Weight Models: Modelle, deren Gewichtungen frei verfügbar sind, z. B. zum Finetuning. Erfahre mehr über Open Weight Modelle.
Overfitting: Modell lernt die Trainingsdaten zu gut auswendig und verliert die Fähigkeit, Wissen auf andere Fälle zu übertragen. Beispiel: Ein Modell zur Erkennung von Katzenbildern erkennt nicht nur die Katze, sondern gewöhnt sich auch „unbewusst“ an den Hintergrund oder die Bildqualität, sodass es Probleme hat, Katzen in anderer Umgebung zu erkennen. Erfahre mehr über Overfitting.
Parameter: Interne Zahlenwerte, mit denen das Modell während des Trainings lernt, Muster zu erkennen und Entscheidungen zu treffen. Je mehr Parameter ein Modell hat, desto mehr Wissen und Zusammenhänge kann es potenziell speichern und verarbeiten. Erfahre mehr über Parameter.
Perplexity: Ein Maß für die Unsicherheit eines Sprachmodells bei der Vorhersage des nächsten Wortes (= Tokens). Je niedriger die Perplexity, desto weniger „verwirrt“ das Modell beim Festlegen des nächsten Wortes. Ein Modell mit niedriger Perplexity versteht also den Kontext besser und kann flüssigere, passendere Texte erzeugen. Erfahre mehr über Perplexity.
Precision: Die Kennzahl zur Bewertung der Genauigkeit innerhalb der Positiven der Modellleistung. Sie beschreibt den Anteil aller positiven Vorhersagen, die tatsächlich positiv waren. Beispiel: Deine KI markiert 20 E-Mails als Spam-Mails, davon waren 15 tatsächlich Spam-Mails ➡️ Precision = 15 / 20 = 75 %. Erfahre mehr über Precision.
Presence-Penalty: Eine Einstellung in Sprachmodellen, die beeinflusst, wie sehr das Modell dazu ermutigt wird, neue Wörter, Themen oder Konzepte in seine Antwort einzubringen. Je höher der Wert der Presence-Penalty, desto eher neigt das Modell dazu, neue Begriffe und Inhalte zu verwenden. Bei einem niedrigen Wert nutzt das Modell häufig die gleichen Wörter, was aber z. B. bei fachlich fokussierten Antworten nützlich sein kann. Erfahre mehr über Presence Penalty.
Prompt: Eine Eingabeaufforderung, mit der man einem Sprachmodell eine Aufgabe stellt. Erfahre mehr über Prompts.
Prompt Engineering: Die Kunst, Eingaben (Prompts) so zu gestalten, dass ein Sprachmodell gewünschte Ausgaben liefert. Erfahre mehr über Prompt Engineering.
Prompt Injection: Die Manipulation eines Modells durch gezielte Texteingabe, um die Kontrolle zu übernehmen. Erfahre mehr über Prompt Injection.
Prompt Patterns: Wiederkehrende Vorgaben oder bewährte Strukturen, nach denen man Prompts für ein Sprachmodell formuliert, um besonders zuverlässig gute Antworten zu erhalten. Erfahre mehr …
Recall: Die Kennzahl zur Messung der Trefferquote bei den Positiven innerhalb eines Modells. Sie beschreibt, wie viele der positiven Fälle die KI tatsächlich erkannt hat. Beispiel: Es gibt 30 Spam-Mails, davon hat deine KI 15 richtig erkannt ➡️ Recall = 15 / 30 =50 %. Erfahre mehr über Recall.
Red Teaming: Ein gezielter Sicherheitstest, bei dem Expertinnen und Experten das KI-System wie ein „Feind“ angreifen, um Schwachstellen zu identifizieren. Beispielsweise verwenden sie gezielt gefährliche oder manipulative Eingaben, um herauszufinden, ob ein Modell vertrauliche Informationen preisgibt. Ziel ist es, diese Sicherheitslücken anschließend zu schließen. Erfahre mehr über Red Teaming.
Retrieval Augmented Generation (RAG): Eine Technik, bei der ein Sprachmodell externe Informationsquellen (z. B. Artikel oder Blogs) abruft und in seine Antwort mit einbezieht. Statt nur auf gespeichertes Trainingswissen zu setzen, können so aktuelles und spezifisches Wissen genutzt werden, das in einer Datenbank, Suchmaschine oder Dokumentensammlung hinterlegt ist. Erfahre mehr über RAG.
Safety Guardrails: Mechanismen zur Verhinderung schädlicher oder unerwünschter Outputs. Erfahre mehr über Safety Guards.
Search Generative Engine (SGE): Eine Suchmaschine, die Suchergebnisse mithilfe generativer KI nicht nur auflistet, sondern direkt in eigenen, formulierten Antworten zusammenfasst. Sie kombiniert klassische Websuche mit Textgenerierung, um Nutzern schnellere und kontextreichere Informationen zu liefern. Erfahre mehr über SGE.
Semantischer Raum: Eine mathematische Darstellung, in der Bedeutungen von Wörtern, Sätzen oder Konzepten als Punkte in einem mehrdimensionalen Raum abgebildet werden. Wörter mit ähnlicher Bedeutung liegen in diesem Raum nahe beieinander, während unterschiedliche Bedeutungen weiter entfernt sind. Erfahre mehr über semantische (Vektor-) Räume.
Stop Sequences: Spezielle Token (Wörter oder Codes), die das Modell dazu bringen, die Ausgabe zu beenden. Erfahre mehr über Stop Sequences.
System-Prompt: Eine Vorgabe, die das Verhalten eines Modells dauerhaft beeinflusst. Erfahre mehr über System Prompts.
Temperatur (Temperature): Ein Parameter, der die Kreativität der Ausgabe beeinflusst (höher = kreativer). Steuert die Zufälligkeit der Outputs. Erfahre mehr über Temperature.
Testdaten / Validierungsdaten: Datensätze, die verwendet werden, um die Leistung eines Modells nach dem Training zu überprüfen. Erfahre mehr über Testdaten.
Throughput: Wird auch Datendurchsatz genannt und beschreibt die Anzahl der Anfragen, die ein Modell pro Sekunde verarbeiten kann. Erfahre mehr über den Throughput.
Token: Die kleinste Verarbeitungseinheit, in die ein Text vom Modell zerlegt wird, bevor er analysiert bzw. erzeugt wird. Abhängig von der Sprache und der Tokenisierungs-Methode, kann die Einheit ein ganzes Wort, ein Wortteil oder auch nur ein Zeichen sein. Beispiel: „Häuser“ kann in zwei Tokens, „Haus“ und „er“, aufgeteilt werden. Erfahre mehr über Token.
Tokenisierung: Der Vorgang, bei dem ein NLP die Eingabe der Nutzerin bzw. des Nutzers in einzelne Tokens zerlegt, um die menschliche Sprache besser verstehen zu können. Erfahre mehr über Tokenisierung.
Top-p (Nucleus Sampling): Eine Sampling-Methode, mit der ein Sprachmodell entscheidet, welches Wort als nächstes erzeugt wird. Dabei wird nicht immer das Wahrscheinlichste genommen, sondern er wählt aus einer Auswahl an Wörtern, deren kumulierte Wahrscheinlichkeit den Wert „p“ ergibt, zufällig eines aus. Da so nicht immer das Top-Wort genommen wird, wird die Ausgabe abwechslungsreicher. Gleichzeitig wird sie aber auch nicht komplett willkürlich, da nur relevante Optionen in der Auswahl landen. Erfahre mehr über Top-P.
Toxicity Detection: Erkennung von beleidigenden, diskriminierenden oder gefährlichen Inhalten. Erfahre mehr über Toxicity Detection.
Training: Das wiederholte Anpassen der Gewichte auf Basis von Trainingsdaten. Daraus lernt das Modell, Muster zu erkennen und komplexe Aufgaben zu lösen, wie Bilder zu identifizieren, Sprache zu verstehen oder Texte zu erzeugen. Erfahre mehr überTraining von KI.
Trainingsdaten: Die Daten, mit denen ein ML-Modell während des Trainingsprozesses gefüttert wird. Erfahre mehr über die Trainingsdaten.
Underfitting: Das Modell ist zu wenig trainiert. Es erkennt keine Muster und übersieht folglich wichtige Details. Beispiel: Ein KI-Modell zur Bilderkennung von Hunden und Katzen tippt immer auf „Hund“, weil es nicht genug Merkmale gelernt hat, um beide zuverlässig zu unterscheiden. Erfahre mehr über Underfitting.
Vektordatenbank: Eine Datenbank, die Informationen als Vektoren speichert, um Ähnlichkeitssuchen zu ermöglichen. Erfahre mehr über Vektordatenbanken.
Zero-Click-Search: Eine Suchanfrage, bei der ein:e Nutzer:in die Antwort direkt in den Suchergebnissen erhält, beispielsweise in einem AI-Overview oder auch klassisch in einem Featured Snippet. Erfahre mehr über Zero-Click-Searches.
Damit du mit den ganzen Abkürzungen nicht durcheinander kommst, haben wir hier noch ein Abkürzungs Cheat Sheet für dich.
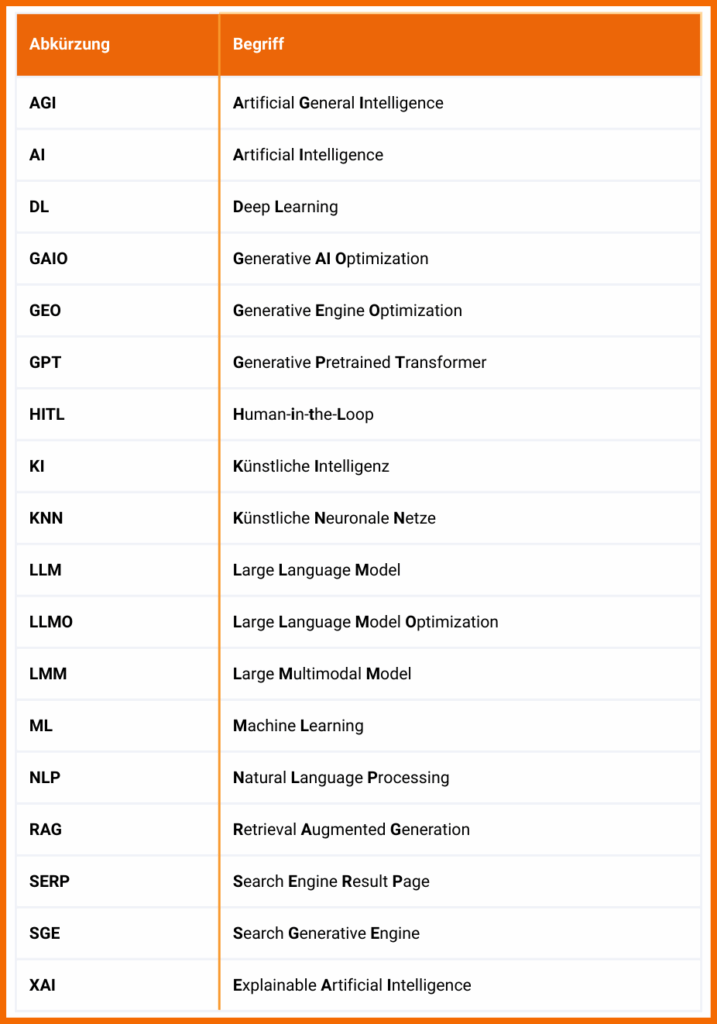
Vermisst du eine Definition? Verrate es uns in den Kommentaren.
Dieser Artikel wurde KI-unterstützt erstellt und durch menschliche Fachkenntnis überarbeitet und optimiert.
Wie hilfreich ist dieser Artikel für dich?
Noch ein Schritt, damit wir besser werden können: Bitte schreibe uns, was dir am Beitrag nicht gefallen hat.
Noch ein Schritt, damit wir besser werden können: Bitte schreibe uns, was dir am Beitrag nicht gefallen hat.
Vielen Dank für dein Feedback! Es hilft uns sehr weiter.

gar nicht hilfreich

weniger hilfreich

eher hilfreich

sehr hilfreich

ich habe ein anderes Thema gesucht